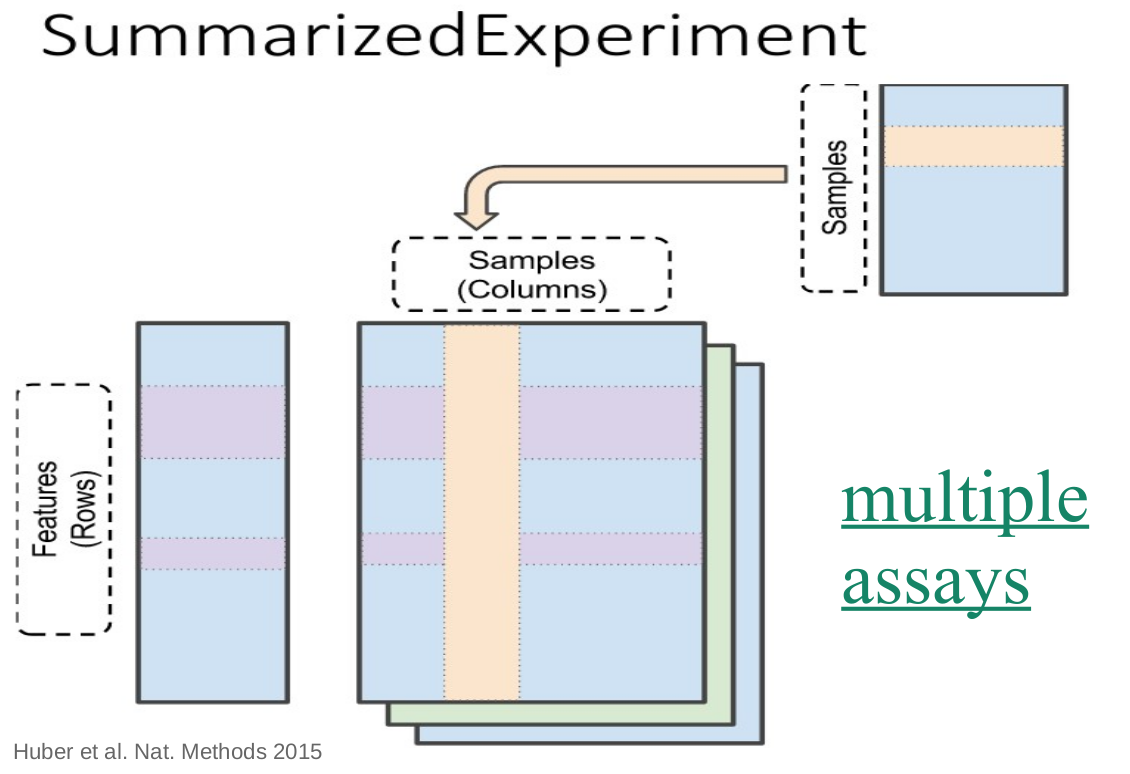
The first microbome data container from around 2010.
Has become standard for (16S) microbiome bioinformatics in R (J McMurdie, S Holmes et al.)
TreeSummarizedExperiment
New, alternative microbiome data container.
Extension to SummarizedExperiment
Optimal for microbiome data
Links microbiome field to larger SummarizedExperiment family
Huang et al. F1000, 2021
Orchestrating Microbiome Analysis with R and Bioconductor – online book: beta version
Current framework
(Tree)SummarizedExperiment for single omics
MultiAssayExperiment for multi-omics
MultiAssayExperiment
Links (Tree)SummarizedExperiment objects
Ramos et al. Cancer Res., 2017
Task: load microbiome data
Load an example data set from the mia R package with:
library(mia)data(HintikkaXOData)
Source: Hintikka et al. (2021). Xylo-oligosaccharides in prevention of hepatic steatosis and adipose tissue inflammation: Associating taxonomic and metabolomic patterns in fecal microbiomes with biclustering. International Journal of Environmental Research and Public Health 18(8) https://doi.org/10.3390/ijerph18084049
Task: load microbiome data
This is MultiAssayExperiment data object. Let us check what experiment it contains.
mae <- HintikkaXODataexperiments(mae)
ExperimentList class object of length 3:
[1] microbiota: TreeSummarizedExperiment with 12706 rows and 40 columns
[2] metabolites: TreeSummarizedExperiment with 38 rows and 40 columns
[3] biomarkers: TreeSummarizedExperiment with 39 rows and 40 columns
Task: load microbiome data
Let us pick the microbiota data, which is TreeSummarizedExperiment object.