Authors: Tuomas Borman1
Last modified: 22 June, 2025.
![]()
![]()
Overview
Description
This training session introduces Bioconductor tools for microbiome data science through a practical case study. It focuses on a framework built around the TreeSummarizedExperiment data container, designed for improved efficiency, scalability, and data integration. Participants will gain hands-on experience with common analysis and visualization methods using the mia package family, along with other interoperable tools from the Bioconductor ecosystem. After the session, participants can continue learning through the freely available Orchestrating Microbiome Analysis (OMA) online book.
Pre-requisites
To get most of the training session, you should meet the following pre-requisites.
- You have a basic understanding of R. You have written simple R scripts or used Quarto/RMarkdown documents.
- You are familiar with Bioconductor.
- You have basic understanding on what the microbiome is.
If your time allows, we recommend to spend some time to explore beforehand Orchestrating Microbiome Analysis (OMA) online book.
Participation
Participants are encouraged to ask questions throughout the workshop. The session will follow a tutorial, with participants running the tutorial alongside the instructor.
To facilitate this, Galaxy & Bioconductor provide pre-installed virtual machines with all necessary packages.
R / Bioconductor packages used
In this training session, we will cover a common methods and packages for microbiome data science in SummarizedExperiment ecosystem. We will have specific focus on mia, which provides essential methods for conducting microbiome analysis.
Time outline
| Activity | Time |
|---|---|
| Practicalities and background | 15m |
| Trained-guided live coding | 45m |
| Time to try things out on your own | 15m |
| Questions, discussion and recap | 15m |
Learning goals and objectives
Questions
- What is mia and OMA?
- How microbiome data science is conducted in SummarizedExperiment ecosystem?
- What benefits this new ecosystem have compared to previous approaches?
Objectives
Analyze and apply methods: Apply the SummarizedExperiment ecosystem to process and analyze microbiome data.
Create visualizations: Generate and interpret visualizations.
Explore documentation: Use the OMA to explore additional tools and methods.
Training session
Background
Microbiome data science
In microbiome research, researchers study interactions between microbes and their hosts, such as humans. Because of the intricate nature of these relationships, computational methods are essential.
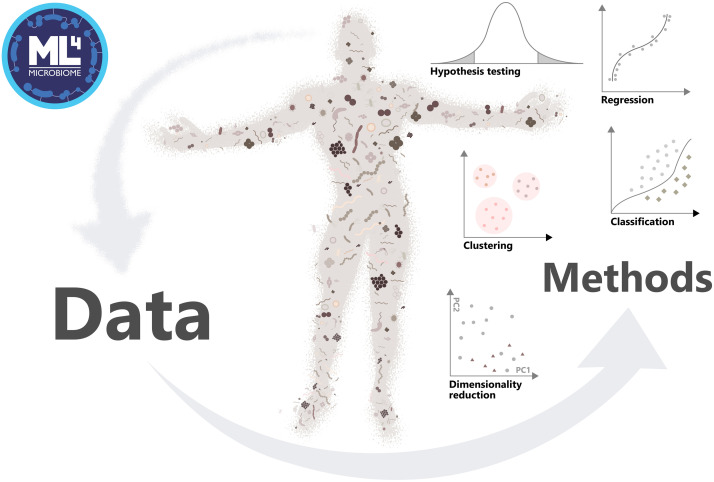
Microbiome-related data containers and ecosystems in Bioconductor
Data containers provide a structured and standardized way to represent complex datasets. This is particularly important in biological research, where a single data table is often insufficient to capture the full richness of a dataset.
Over the years, several approaches to data organization have been developed. One of the first widely adopted data containers in microbiome research was phyloseq (McMurdie and Holmes 2013), designed for 16S amplicon sequencing data. However, it has limitations, particularly in linking multiple experiments and ensuring interoperability between tools in Bioconductor.
SummarizedExperiment (SE) (Huber et al. 2015), on the other hand, was introduced as a general-purpose container for biological data and has become the most widely used format within the Bioconductor ecosystem. It has since been extended to more specialized formats, including SingleCellExperiment (Amezquita et al. 2020) for single-cell data and TreeSummarizedExperiment (TreeSE) (Huang et al. 2021), which is tailored for microbiome datasets.
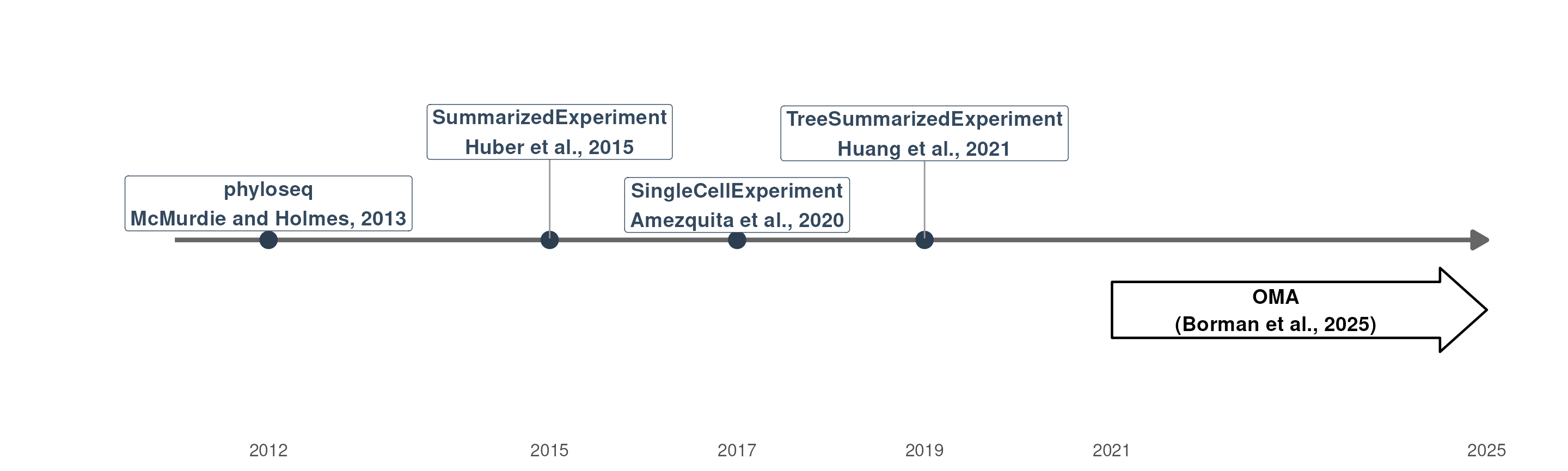
Timeline of microbiome-related data containter in Bioconductor
Ochestrating Microbiome Analysis with Bioconductor (OMA)
- mia (Data analysis)
- miaViz (Visualization)
- miaSim (Simulation)
- miaTime (Time series analysis)
- miaDash (Graphical user interface)
- iSEEtree (Interactive visualization)
- Expanded by independent developers
Interoperable with the SummarizedExperiment ecosystem
![]()
![]()
![]()






![]()
![]()


Trained-guided live coding
Start your engines!
- Go to workshop.bioconductor.org
- Or prepare your local R session
Import data
The curated metagenomic data project provides free access to a
collection of curated microbiome datasets, which are available through
the curatedMetagenomicData R package (Pasolli et al. 2017). Currently, it contains
over 20,000 samples from 100 studies, which can be imported directly to
TreeSE format. You can see the full list of available
datasets from the
documentation.
Below, we we load a dataset containing 60 samples from healthy controls and patients with colorectal cancer (CRC).
library(curatedMetagenomicData)
res <- curatedMetagenomicData(
pattern = "GuptaA_2019.relative_abundance",
dryrun = FALSE,
rownames = "short"
)Once loaded, we can see that the data includes a list of single
TreeSummarizedExperiment
object, which including taxonomy annotations. We select it from the list
and store it into a variable named tse.
tse <- res[[1]]Data container
TreeSummarizedExperiment
extends SummarizedExperiment
class by adding a support for microbiome-specific datatypes. These
include, for instance, rowTree slot that can be utilized to
store phylogeny or any other hierarchical presentation of the data. All
slots derived from SummarizedExperiment
class are also available in TreeSummarizedExperiment,
providing full backward compatibility.
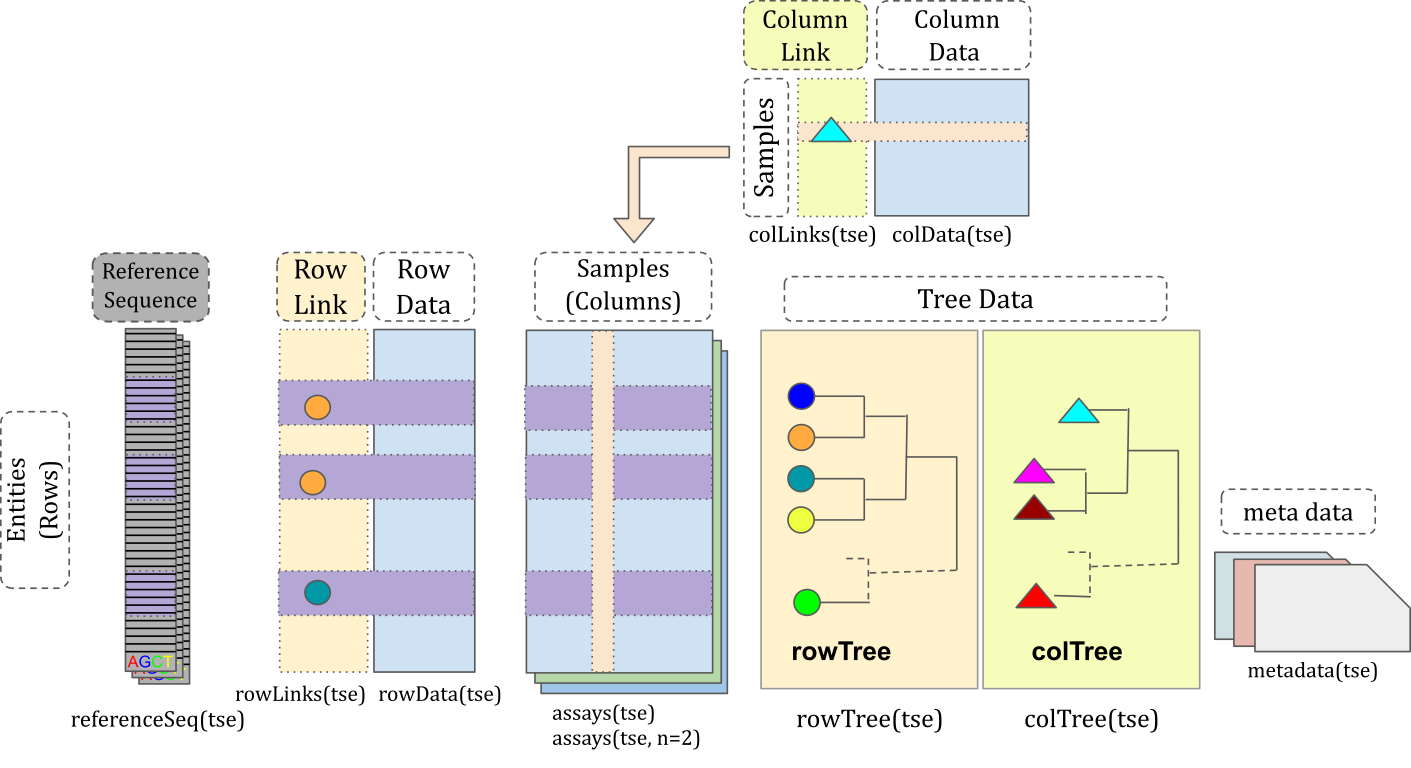
tse
#> class: TreeSummarizedExperiment
#> dim: 308 60
#> metadata(0):
#> assays(1): relative_abundance
#> rownames(308): species:Escherichia coli species:Alistipes putredinis
#> ... species:Campylobacter ureolyticus species:Prevotella sp. oral
#> taxon 376
#> rowData names(7): superkingdom phylum ... genus species
#> colnames(60): GupDM_A_11 GupDM_A_15 ... GupDM_JO GupDM_JP
#> colData names(27): study_name subject_id ... disease_stage
#> disease_location
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> rowLinks: a LinkDataFrame (308 rows)
#> rowTree: 1 phylo tree(s) (10430 leaves)
#> colLinks: NULL
#> colTree: NULLSlots can be accessed with dedicated accessor functions. For
instance, colData (sample metadata) can be accessed with
colData() function.
# Show only first five rows and columns
colData(tse)[1:5, 1:5]
#> DataFrame with 5 rows and 5 columns
#> study_name subject_id body_site antibiotics_current_use
#> <character> <character> <character> <character>
#> GupDM_A_11 GuptaA_2019 GupDM_A11 stool no
#> GupDM_A_15 GuptaA_2019 GupDM_A15 stool no
#> GupDM_A1 GuptaA_2019 GupDM_A1 stool no
#> GupDM_A10 GuptaA_2019 GupDM_A10 stool no
#> GupDM_A12 GuptaA_2019 GupDM_A12 stool no
#> study_condition
#> <character>
#> GupDM_A_11 CRC
#> GupDM_A_15 CRC
#> GupDM_A1 CRC
#> GupDM_A10 CRC
#> GupDM_A12 CRCData processing
Microbiome data has unique characteristics, meaning that dealing with
such data also poses unique challenges and approaches. The
mia package provides methods for performing common
operations on microbiome data within the SE ecosystem.
For instance, agglomeration is commonly used to reduce the number of features or to focus on biologically meaningful subgroups of the data. Agglomeration means merging data into higher taxonomic levels by summing the abundances of related taxa.
Below, we agglomerate the data into all available taxonomy levels.
library(mia)
tse <- agglomerateByRanks(tse)At first glance, it might seem that nothing has changed. However, the
agglomerated data is stored in the altExp slot. This slot
keeps track of the sample mapping and stores different versions of the
data.
We can access data agglomeration into the phylum level with the following command:
altExp(tse, "phylum")
#> class: TreeSummarizedExperiment
#> dim: 11 60
#> metadata(1): agglomerated_by_rank
#> assays(1): relative_abundance
#> rownames(11): Actinobacteria Bacteroidota ... Synergistetes
#> Verrucomicrobia
#> rowData names(7): superkingdom phylum ... genus species
#> colnames(60): GupDM_A_11 GupDM_A_15 ... GupDM_JO GupDM_JP
#> colData names(27): study_name subject_id ... disease_stage
#> disease_location
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> rowLinks: a LinkDataFrame (11 rows)
#> rowTree: 1 phylo tree(s) (11 leaves)
#> colLinks: NULL
#> colTree: NULLThe data looks similar to original data; only the number of rows has
changed. While we could store the phylum-level data in a separate
variable, it’s better to keep it in the altExp slot, as it
maintains consistent sample mapping for us.
Another data processing step where microbiome analysis has unique approaches is transformation. Below, we apply centered lo-ratio (CLR) transformation which respect the compositional nature of microbiome data.
tse <- transformAssay(
tse,
assay.type = "relative_abundance",
method = "clr",
pseudocount = TRUE
)The transformed abundance table is stored in the assay
slot. This slot now contains two tables: the original abundance table
and the CLR-transformed table We can access the transformed data with
the following command:
assay(tse, "clr")[1:5, 1:5]
#> GupDM_A_11 GupDM_A_15 GupDM_A1 GupDM_A10
#> species:Escherichia coli 10.178496 11.6516053 8.595739 10.189020
#> species:Alistipes putredinis 9.652743 -0.5960068 5.186345 -1.540499
#> species:Porphyromonas asaccharolytica 8.918831 -0.5960068 4.300300 -1.540499
#> species:Bacteroides uniformis 8.903202 -0.5960068 5.464096 -1.540499
#> species:Prevotella stercorea 8.773817 -0.5960068 5.231728 -1.540499
#> GupDM_A12
#> species:Escherichia coli 7.042800
#> species:Alistipes putredinis -1.410307
#> species:Porphyromonas asaccharolytica -1.410307
#> species:Bacteroides uniformis 5.473920
#> species:Prevotella stercorea 3.672227Community summaries
While mia package include common methods for analysis, miaViz provides methods for visualizing microbiome data. For instance, we can visualize abundance of phyla with a bar plot. To compare controls and CRC patients, we can visualize the groups separately.
library(miaViz)
# Get phylum-level data
tse_phyla <- altExp(tse, "phylum")
# Create a bar plot
plotAbundance(
tse_phyla,
assay.type = "relative_abundance",
col.var = "disease",
facet.cols = TRUE,
scales = "free"
)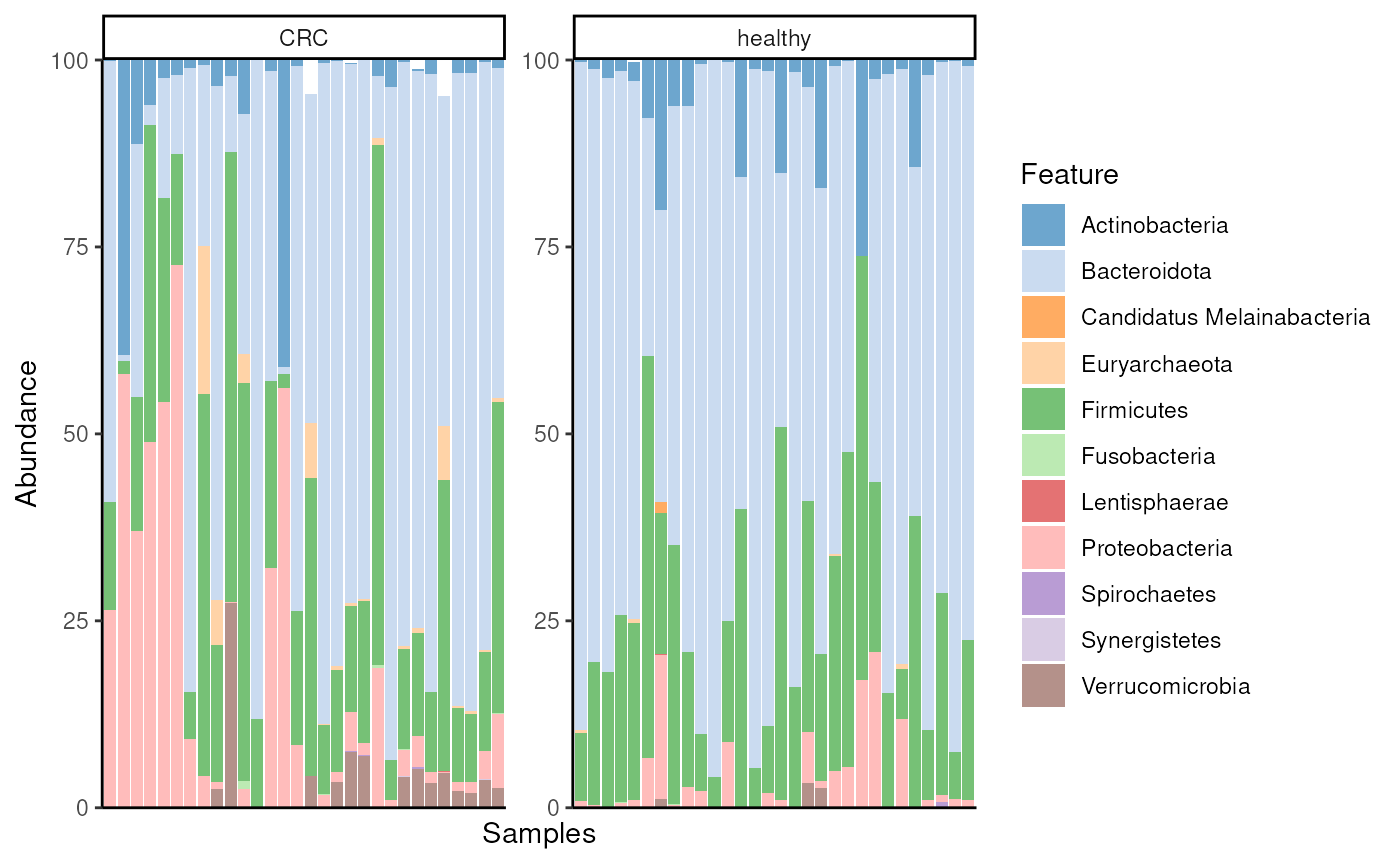
From the figure, we observe that especially abundance of Euryarchaeota seems to differ between the groups.
Alpha diversity
To summarize the diversity of microbial communities, alpha diversity is commonly calculated. There are several diversity indices available, all of which measure the number of distinct taxa and how evenly their abundances are distributed, each with a different emphasis.
tse <- addAlpha(tse, assay.type = "relative_abundance")The results are stored in colData. By default,
addAlpha() returns a set of indices that considers
different aspects of diversity. Below, we visualize Faith’s diversity
that assess the phylogenetic diversity of samples.
library(scater)
plotColData(tse, x = "disease", y = "faith_diversity")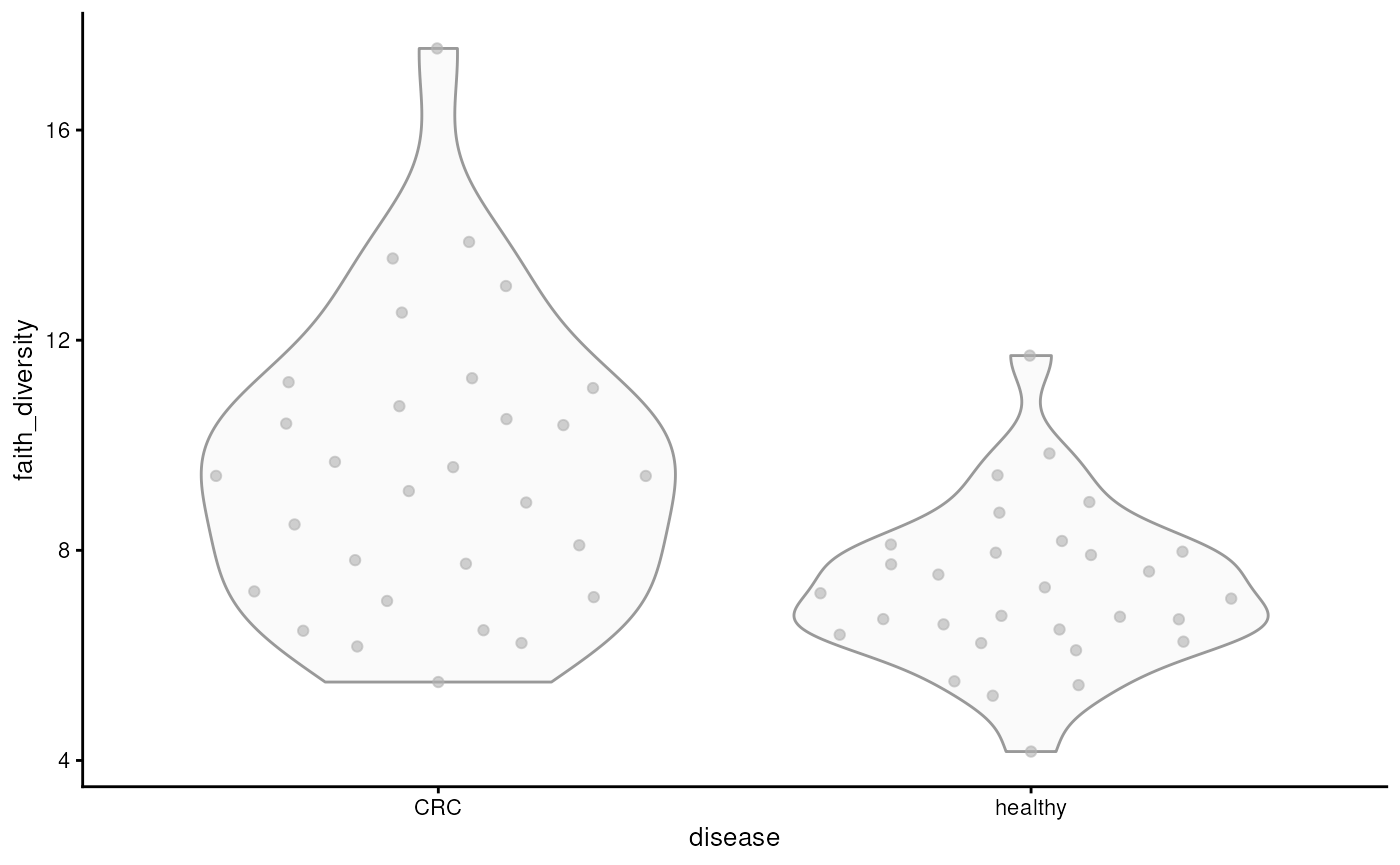
From the figure, we can observe that CRC patients have more diverse microbiomes. This may suggest that their gut is colonized by microbes that are not typically present in a healthy gut.
Beta diversity
While alpha diversity reflects within-sample diversity, beta diversity measures diversity between samples. This allows us to assess whether there are patterns in microbial profiles associated with covariates — such as diagnosis, in this case.
Below, we calculate perform principal coordinate analysis (PCoA) also known as multidimensional scaling (MDS). We apply UniFrac dissimilarity that takes into account phylogeny.
tse <- addMDS(
tse,
assay.type = "relative_abundance",
method = "unifrac"
)After calculating the results, we can visualize them with the diagnosis.
plotReducedDim(tse, dimred = "MDS", colour_by = "disease")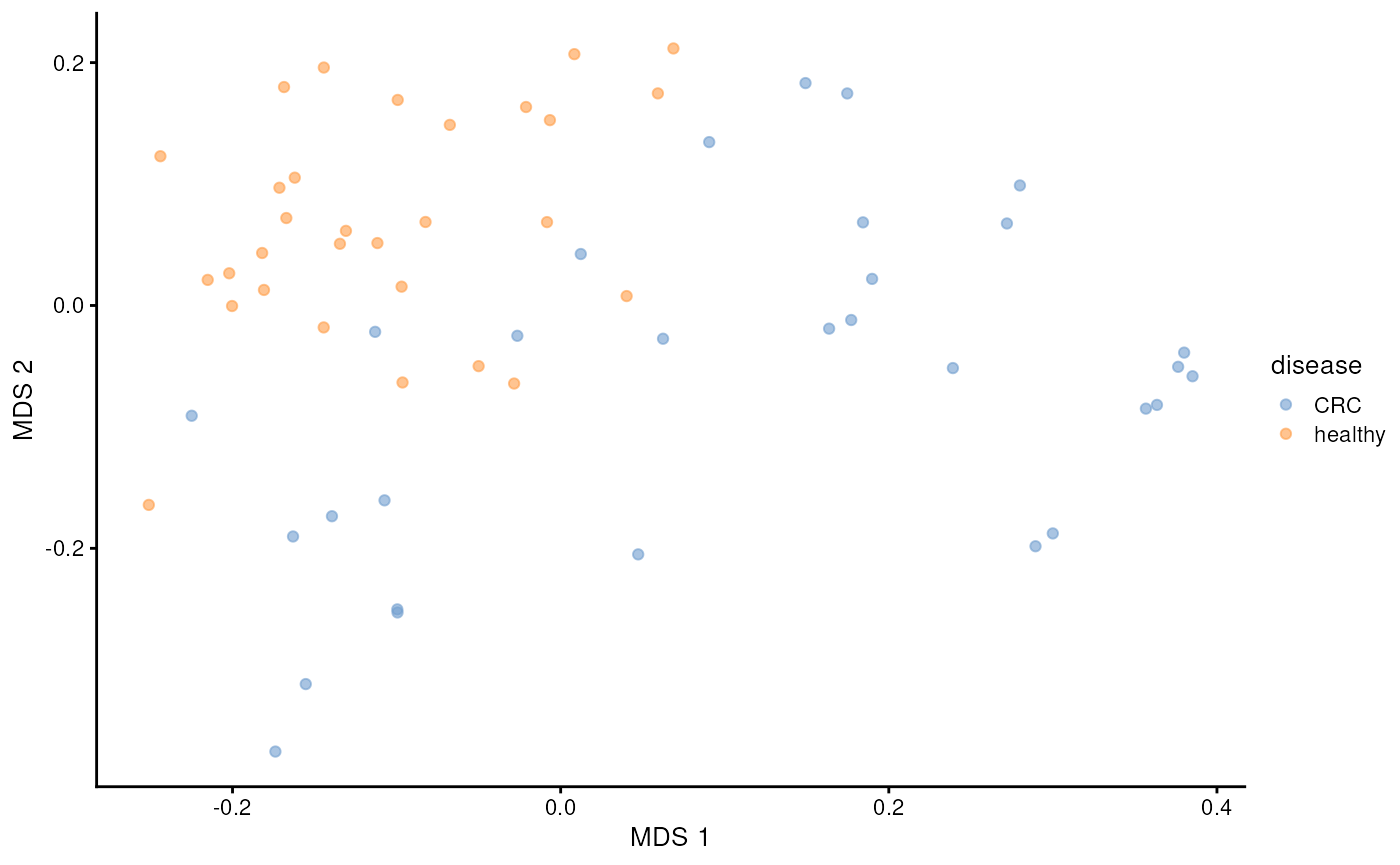
We can see clear pattern: microbial profiles of CRC patients are distinct from healthy controls.
Time to try things out on your own!
- Go to OMA (microbiome.github.io/OMA)
- Navigate to Differential abundance analysis chapter
- Do exercises 4-6
- Explore the book!
Differential abundance analysis
file_path <- file.path("maaslin3_output", "figures", "summary_plot.png")
knitr::include_graphics(file_path)Questions, discussion and recap
- Microbiome data science in SummarizedExperiment ecosystem
- Scalable and computationally efficient
- Integration of multi-table and multi-omics datasets
Thank you for your time!
Join us!
Online book: microbiome.github.io/OMA
Discussion forums: github.com/microbiome/OMA/discussions and Bioconductor Zulip

![]()
Session information
sessionInfo()
#> R Under development (unstable) (2025-12-01 r89083)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.3 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Etc/UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] scater_1.39.0 scuttle_1.21.0
#> [3] miaViz_1.19.1 ggraph_2.2.2
#> [5] mia_1.17.11 MultiAssayExperiment_1.37.2
#> [7] TreeSummarizedExperiment_2.19.0 Biostrings_2.79.2
#> [9] XVector_0.51.0 SingleCellExperiment_1.33.0
#> [11] SummarizedExperiment_1.41.0 Biobase_2.71.0
#> [13] GenomicRanges_1.63.0 Seqinfo_1.1.0
#> [15] IRanges_2.45.0 S4Vectors_0.49.0
#> [17] BiocGenerics_0.57.0 generics_0.1.4
#> [19] MatrixGenerics_1.23.0 matrixStats_1.5.0
#> [21] ggrepel_0.9.6 ggplot2_4.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] RColorBrewer_1.1-3 jsonlite_2.0.0
#> [3] magrittr_2.0.4 TH.data_1.1-5
#> [5] estimability_1.5.1 ggbeeswarm_0.7.3
#> [7] farver_2.1.2 rmarkdown_2.30
#> [9] fs_1.6.6 ragg_1.5.0
#> [11] vctrs_0.6.5 memoise_2.0.1
#> [13] DelayedMatrixStats_1.33.0 ggtree_4.1.1
#> [15] htmltools_0.5.8.1 S4Arrays_1.11.1
#> [17] BiocNeighbors_2.5.0 janeaustenr_1.0.0
#> [19] cellranger_1.1.0 gridGraphics_0.5-1
#> [21] SparseArray_1.11.7 sass_0.4.10
#> [23] parallelly_1.45.1 bslib_0.9.0
#> [25] tokenizers_0.3.0 htmlwidgets_1.6.4
#> [27] desc_1.4.3 plyr_1.8.9
#> [29] DECIPHER_3.7.0 sandwich_3.1-1
#> [31] emmeans_2.0.0 zoo_1.8-14
#> [33] cachem_1.1.0 igraph_2.2.1
#> [35] lifecycle_1.0.4 pkgconfig_2.0.3
#> [37] rsvd_1.0.5 Matrix_1.7-4
#> [39] R6_2.6.1 fastmap_1.2.0
#> [41] tidytext_0.4.3 aplot_0.2.9
#> [43] digest_0.6.39 ggnewscale_0.5.2
#> [45] patchwork_1.3.2 irlba_2.3.5.1
#> [47] SnowballC_0.7.1 textshaping_1.0.4
#> [49] vegan_2.7-2 beachmat_2.27.0
#> [51] labeling_0.4.3 polyclip_1.10-7
#> [53] mgcv_1.9-4 abind_1.4-8
#> [55] compiler_4.6.0 fontquiver_0.2.1
#> [57] withr_3.0.2 S7_0.2.1
#> [59] BiocParallel_1.45.0 viridis_0.6.5
#> [61] DBI_1.2.3 ggforce_0.5.0
#> [63] MASS_7.3-65 rappdirs_0.3.3
#> [65] DelayedArray_0.37.0 bluster_1.21.0
#> [67] permute_0.9-8 tools_4.6.0
#> [69] vipor_0.4.7 beeswarm_0.4.0
#> [71] ape_5.8-1 glue_1.8.0
#> [73] nlme_3.1-168 gridtext_0.1.5
#> [75] grid_4.6.0 cluster_2.1.8.1
#> [77] reshape2_1.4.5 gtable_0.3.6
#> [79] fillpattern_1.0.2 tzdb_0.5.0
#> [81] tidyr_1.3.1 hms_1.1.4
#> [83] tidygraph_1.3.1 BiocSingular_1.27.1
#> [85] ScaledMatrix_1.19.0 xml2_1.5.1
#> [87] pillar_1.11.1 stringr_1.6.0
#> [89] yulab.utils_0.2.2 splines_4.6.0
#> [91] tweenr_2.0.3 dplyr_1.1.4
#> [93] ggtext_0.1.2 treeio_1.35.0
#> [95] lattice_0.22-7 survival_3.8-3
#> [97] tidyselect_1.2.1 DirichletMultinomial_1.53.0
#> [99] fontLiberation_0.1.0 knitr_1.50
#> [101] fontBitstreamVera_0.1.1 gridExtra_2.3
#> [103] xfun_0.54 graphlayouts_1.2.2
#> [105] rbiom_2.2.1 stringi_1.8.7
#> [107] ggfun_0.2.0 lazyeval_0.2.2
#> [109] yaml_2.3.11 evaluate_1.0.5
#> [111] codetools_0.2-20 gdtools_0.4.4
#> [113] tibble_3.3.0 BiocManager_1.30.27
#> [115] ggplotify_0.1.3 cli_3.6.5
#> [117] xtable_1.8-4 systemfonts_1.3.1
#> [119] jquerylib_0.1.4 Rcpp_1.1.0
#> [121] readxl_1.4.5 coda_0.19-4.1
#> [123] parallel_4.6.0 pkgdown_2.2.0
#> [125] readr_2.1.6 sparseMatrixStats_1.23.0
#> [127] slam_0.1-55 decontam_1.31.0
#> [129] viridisLite_0.4.2 mvtnorm_1.3-3
#> [131] tidytree_0.4.6 ggiraph_0.9.2
#> [133] scales_1.4.0 purrr_1.2.0
#> [135] crayon_1.5.3 BiocStyle_2.39.0
#> [137] rlang_1.1.6 cowplot_1.2.0
#> [139] multcomp_1.4-29References
University of Turku, tvborm@utu.fi↩︎