Health, diagnostics and drug development
Bioinformatics and a changing society, 4th December 2025
Source:vignettes/hddd_bioinfo.Rmd
hddd_bioinfo.RmdAuthors: Tuomas Borman1, Matti Ruuskanen
Last modified: 2
December, 2025.

![]()
Overview
Description
Because of the complex nature of microbiome data, robust and reproducible computational approaches are essential. This workshop introduces the latest advances in microbiome analysis within Bioconductor, focusing on the mia (Microbiome Analysis) framework. Participants wil gain hands-on experience with data handling, visualization, and analysis through a practical case study. The workshop will also introduce the Orchestrating Microbiome Analysis (OMA) online book, a freely available resource that promotes best practices and supports adoption of the ecosystem. Together, these resources enable scalable, transparent, and community-driven microbiome data science.
Pre-requisites
To get most of the training session, you should meet the following pre-requisites.
- You have a basic understanding of R. You have written simple R scripts or used Quarto/RMarkdown documents.
- You have basic understanding on what the microbiome is.
If your time allows, we recommend to spend some time to explore beforehand Orchestrating Microbiome Analysis (OMA) online book.
Participation
Participants are encouraged to ask questions throughout the workshop. The session will follow a tutorial, with participants running the tutorial alongside the instructor.
R / Bioconductor packages used
In this training session, we will cover a common methods and packages for microbiome data science in SummarizedExperiment ecosystem. We will have specific focus on mia, which provides essential methods for conducting microbiome analysis.
Time outline
| Activity | Time |
|---|---|
| Practicalities and background | 20m |
| Trained-guided live coding | 40m |
| Break | 10m |
| Trained-guided live coding continues | 40m |
| Questions, discussion and recap | 10m |
| Total | 2h |
Learning goals and objectives
Questions
- What is mia and OMA?
- How microbiome data science is conducted in SummarizedExperiment ecosystem?
- What benefits this new ecosystem have compared to previous approaches?
Objectives
- Analyze and apply methods: Apply the SummarizedExperiment ecosystem to process and analyze microbiome data.
- Create visualizations: Generate and interpret visualizations.
- Explore documentation: Use the OMA to explore additional tools and methods.
Training session
Trained-guided live coding
Start your engines!
Joining the Noppe virtual machine:
- Go to Noppe
- Log in with Haka (University account) or CSC id.
- Click “Join workspace”, ask join code from theinstructor.
- My workspaces -> HDDD Bioinfo 25 -> Click “power button”.
Import data
Below, we import a dataset containing 60 samples from healthy controls and patients with colorectal cancer (CRC). First, we import the data files.
library(ape)
dir_name <- file.path("data", "GuptaA_2019")
# Abundance table
path <- file.path(dir_name, "taxonomy_abundance.csv")
assay <- read.csv(path, row.names = 1L)
# Taxonomy table
path <- file.path(dir_name, "taxonomy_table.csv")
taxonomy_table <- read.csv(path, row.names = 1L)
# Sample metadata
path <- file.path(dir_name, "sample_metadata.csv")
sample_metadata <- read.csv(path, row.names = 1L)
# Phylogeny
path <- file.path(dir_name, "phylogeny.tree")
phylogeny <- read.tree(path)Then we create TreeSummarizedExperiment object. Note: data types must be in specific format.
library(mia)
# Abundance table
assay <- assay |> as.matrix()
assay_list <- SimpleList(counts = assay)
# Taxonomy table and sample metadata
taxonomy_table <- taxonomy_table |> DataFrame()
sample_metadata <- sample_metadata |> DataFrame()
# Construct TreeSE
tse <- TreeSummarizedExperiment(
assays = assay_list,
rowData = taxonomy_table,
colData = sample_metadata,
rowTree = phylogeny
)Data container
TreeSummarizedExperiment
extends SummarizedExperiment
class by adding a support for microbiome-specific datatypes. These
include, for instance, rowTree slot that can be utilized to
store phylogeny or any other hierarchical presentation of the data. All
slots derived from SummarizedExperiment
class are also available in TreeSummarizedExperiment,
providing full backward compatibility.
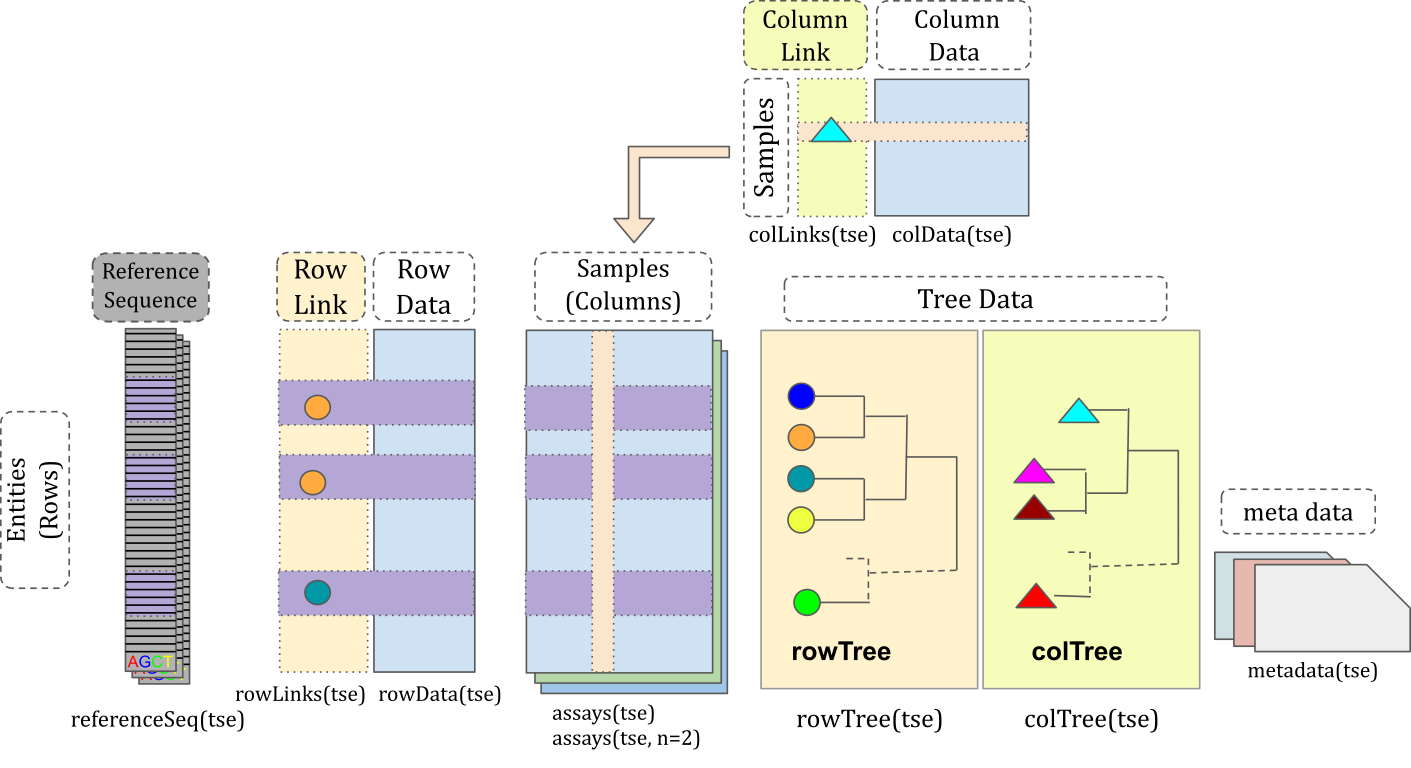
tse
#> class: TreeSummarizedExperiment
#> dim: 308 60
#> metadata(0):
#> assays(1): counts
#> rownames(308): species-Escherichia_coli species-Alistipes_putredinis
#> ... species-Campylobacter_ureolyticus
#> species-Prevotella_sp._oral_taxon_376
#> rowData names(7): superkingdom phylum ... genus species
#> colnames(60): GupDM_A_11 GupDM_A_15 ... GupDM_JO GupDM_JP
#> colData names(27): study_name subject_id ... disease_stage
#> disease_location
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> rowLinks: a LinkDataFrame (308 rows)
#> rowTree: 1 phylo tree(s) (10430 leaves)
#> colLinks: NULL
#> colTree: NULLSlots can be accessed with dedicated accessor functions. For
instance, colData (sample metadata) can be accessed with
colData() function.
# Show only first five rows and columns
colData(tse)[1:5, 1:5]
#> DataFrame with 5 rows and 5 columns
#> study_name subject_id body_site antibiotics_current_use
#> <character> <character> <character> <character>
#> GupDM_A_11 GuptaA_2019 GupDM_A11 stool no
#> GupDM_A_15 GuptaA_2019 GupDM_A15 stool no
#> GupDM_A1 GuptaA_2019 GupDM_A1 stool no
#> GupDM_A10 GuptaA_2019 GupDM_A10 stool no
#> GupDM_A12 GuptaA_2019 GupDM_A12 stool no
#> study_condition
#> <character>
#> GupDM_A_11 CRC
#> GupDM_A_15 CRC
#> GupDM_A1 CRC
#> GupDM_A10 CRC
#> GupDM_A12 CRCThe key functionality of data containers is that it does the sample and feature bookkeeping for us. E.g., we can subset the data container without need for worrying about sample matching between abundance table and sample metadata.
tse[1:10, c(1, 2)]
#> class: TreeSummarizedExperiment
#> dim: 10 2
#> metadata(0):
#> assays(1): counts
#> rownames(10): species-Escherichia_coli species-Alistipes_putredinis ...
#> species-Prevotella_bivia species-Odoribacter_splanchnicus
#> rowData names(7): superkingdom phylum ... genus species
#> colnames(2): GupDM_A_11 GupDM_A_15
#> colData names(27): study_name subject_id ... disease_stage
#> disease_location
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
#> rowLinks: a LinkDataFrame (10 rows)
#> rowTree: 1 phylo tree(s) (10430 leaves)
#> colLinks: NULL
#> colTree: NULLData processing
Microbiome data has unique characteristics, meaning that dealing with such data also poses unique challenges and approaches. The mia package provides methods for performing common operations on microbiome data within the SummarizedExperiment ecosystem.
Transformation
Microbiome data is typically zero-inflated, meaning that there are lots of unobserved features. Let’s first visualize the distribution of counts.
library(miaViz)
plotHistogram(tse, assay.type = "counts")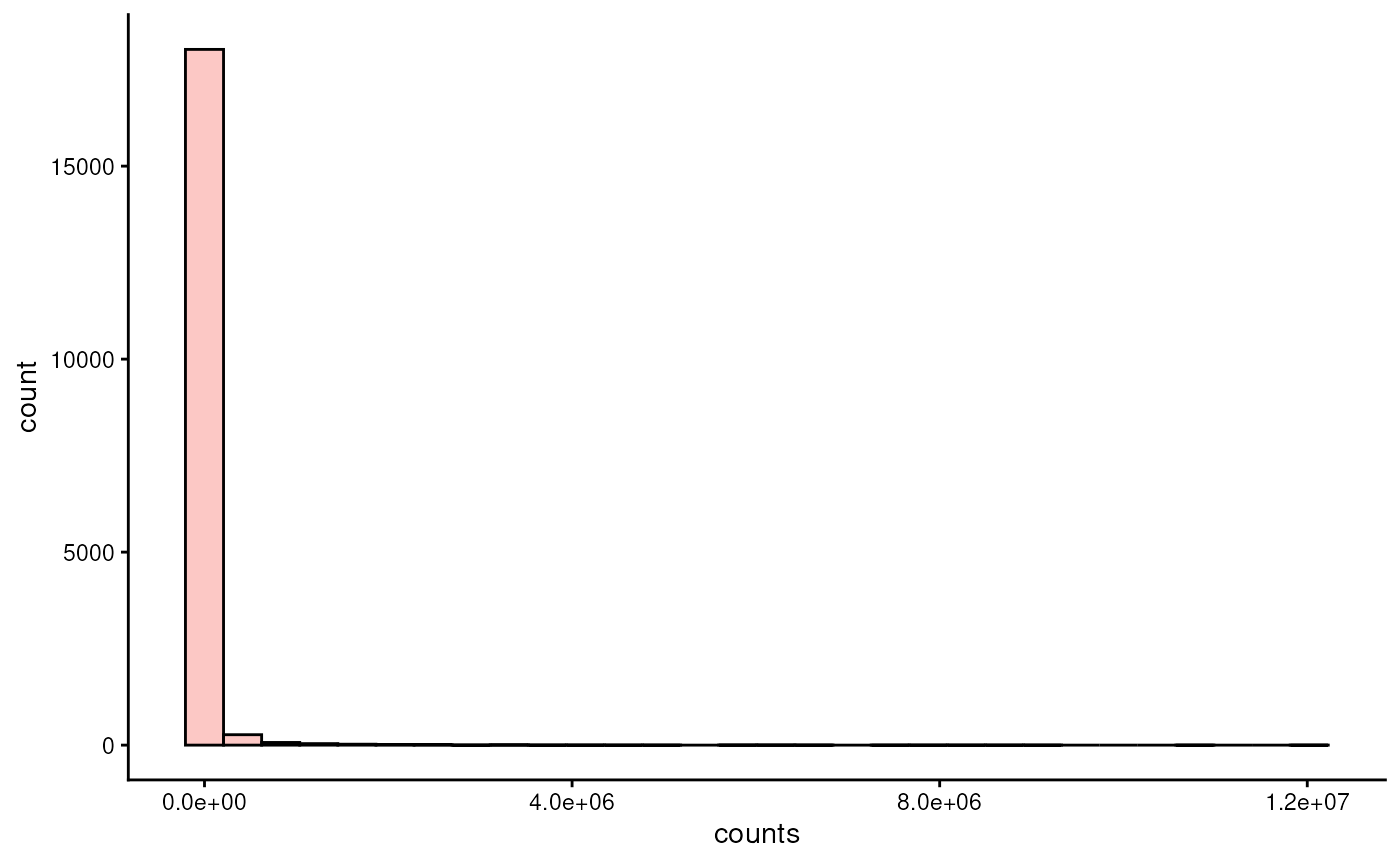
As we can see, the distribution is highly right-skewed. To make the data more normally-distributed, one can apply centered log-ratio transformation.
tse <- transformAssay(
tse,
assay.type = "counts",
method = "rclr"
)And when we visualize the distribution…
plotHistogram(tse, assay.type = "rclr")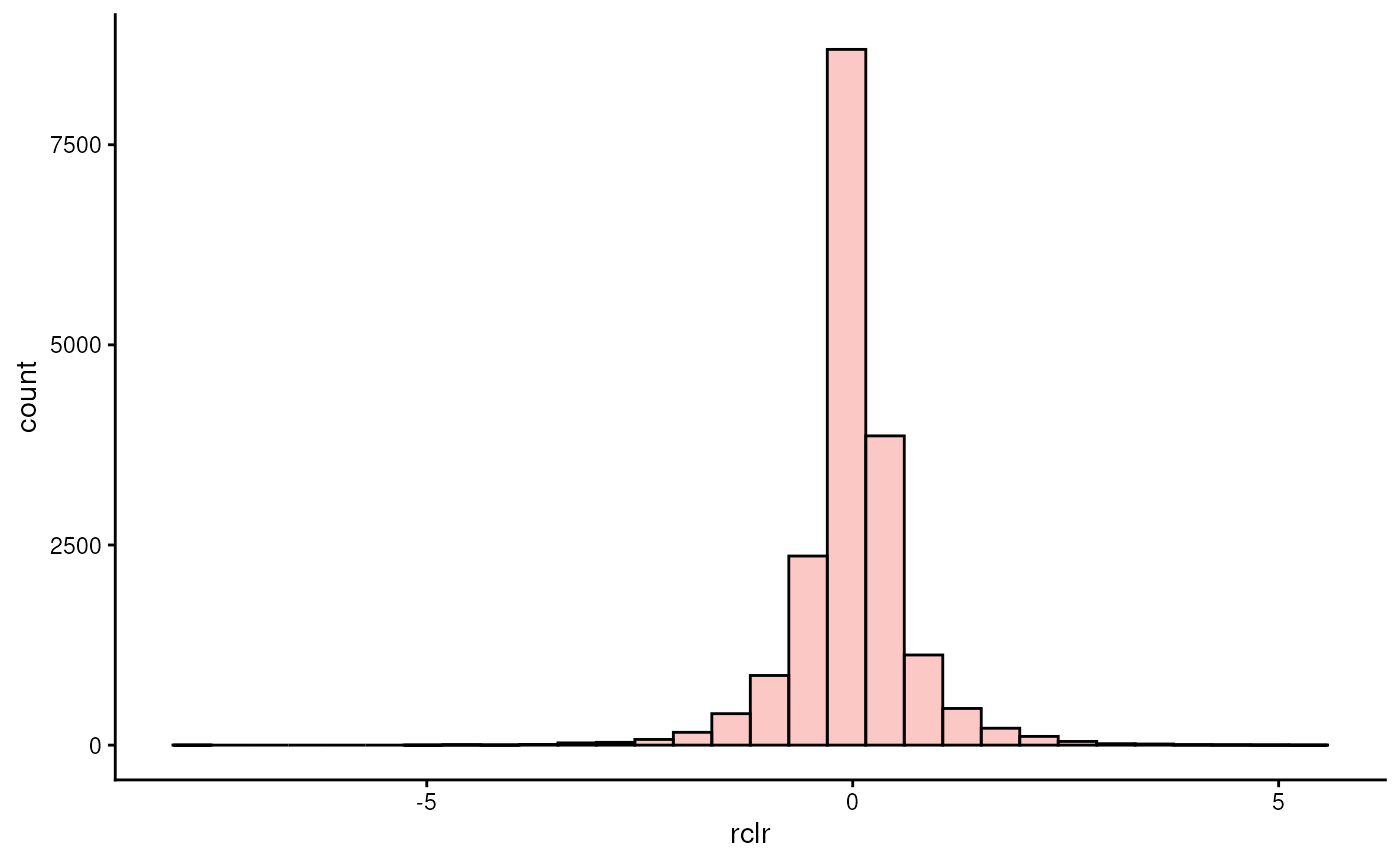
… we see that the data is centered at zero and exhibit a distribution that is more similar to normal than before.
We can access the transformed data with the following command:
assay(tse, "rclr")[1:5, 1:5]
#> GupDM_A_11 GupDM_A_15 GupDM_A1
#> species-Escherichia_coli 1.0405323 1.7524587 4.7246937
#> species-Alistipes_putredinis 0.6682048 1.3053407 2.9612780
#> species-Porphyromonas_asaccharolytica 0.2550027 0.4543376 1.1921391
#> species-Bacteroides_uniformis 0.1124889 -0.1080770 1.6061997
#> species-Prevotella_stercorea -0.8488226 -2.0823495 -0.7709126
#> GupDM_A10 GupDM_A12
#> species-Escherichia_coli 3.3080000 1.3616062
#> species-Alistipes_putredinis 2.1785187 1.2769549
#> species-Porphyromonas_asaccharolytica 0.8447763 0.4077736
#> species-Bacteroides_uniformis 0.8531567 -0.1121646
#> species-Prevotella_stercorea -1.2032669 -1.3964826Alpha diversity
Alpha diversity indices can be calculated with
addAlpha().
tse <- addAlpha(tse, assay.type = "counts")The results are stored in colData. By default, the
function returns a set of indices that considers different aspects of
diversity. Below, we visualize Faith’s diversity that assess the
phylogenetic diversity of samples.
plotBoxplot(tse, col.var = "faith_diversity", x = "disease")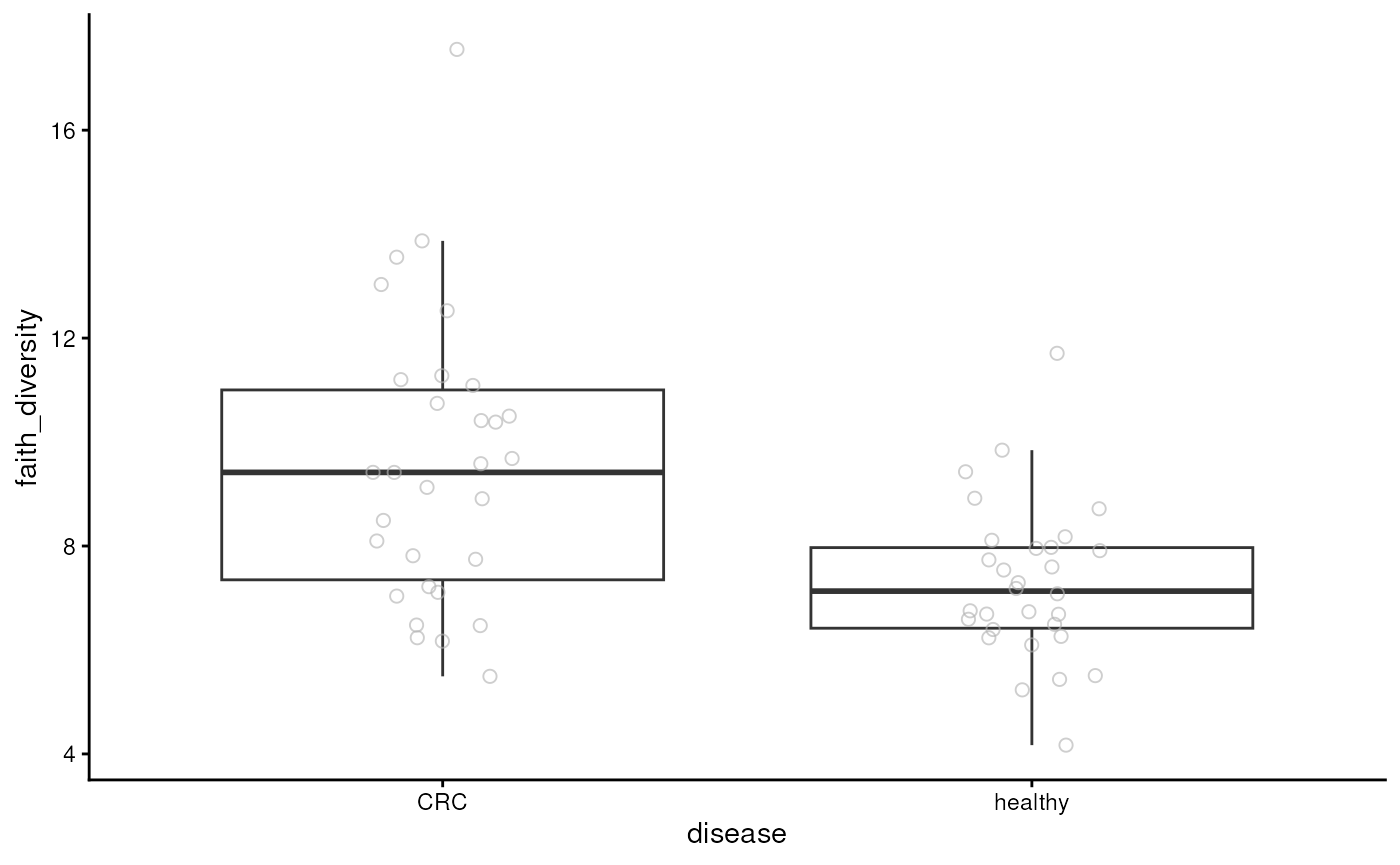
From the figure, we can observe that CRC patients have more diverse microbiomes. This may suggest that their gut is colonized by microbes that are not typically present in a healthy gut.
Beta diversity
A common beta diversity method is Principal Coordinate Analysis (PCoA) also known as Multi-dimensional Scaling (MDS). It is unsupervised technique that can be utilized to find patterns from the data.
tse <- addMDS(
tse,
assay.type = "counts",
method = "unifrac"
)PCoA results are commonly visualized with a scatter plot. Here we color points based on disease.
library(scater)
plotReducedDim(tse, dimred = "MDS", colour_by = "disease")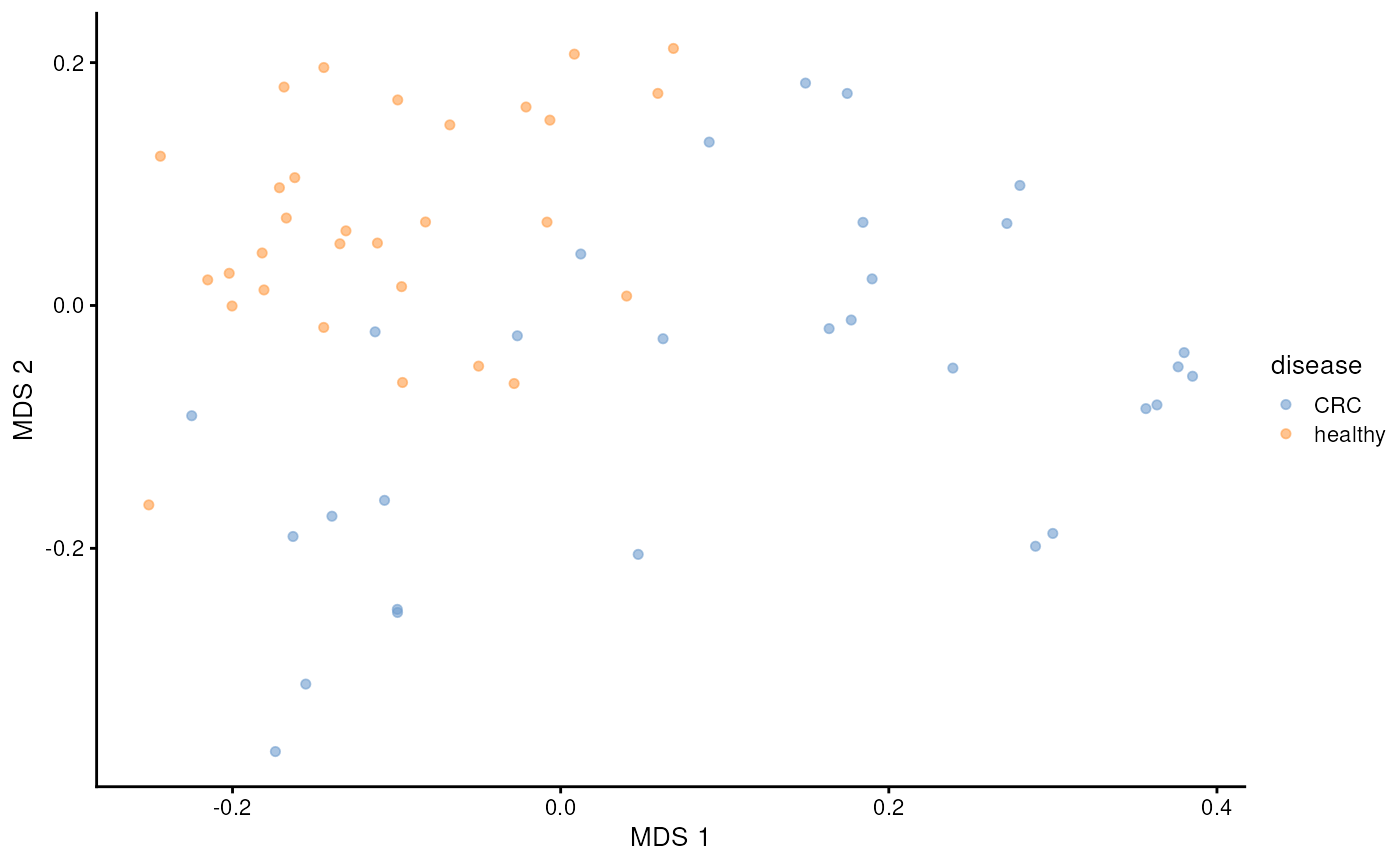
We can see clear pattern. CRC patients’ microbiome profile seem to differ from healthy ones.
Next, we can utilize distance-based Redundancy Analysis (dbRDA). It is similar to PCoA, but it specifically aims to assess how much variance or association is accounted to sample covariates.
tse <- addRDA(
tse,
assay.type = "rclr",
method = "euclidean",
formula = x ~ disease + gender
)Similarly, we can visualize the results with a biplot, specific type of scatter plot.
plotRDA(tse, dimred = "RDA", colour.by = "disease")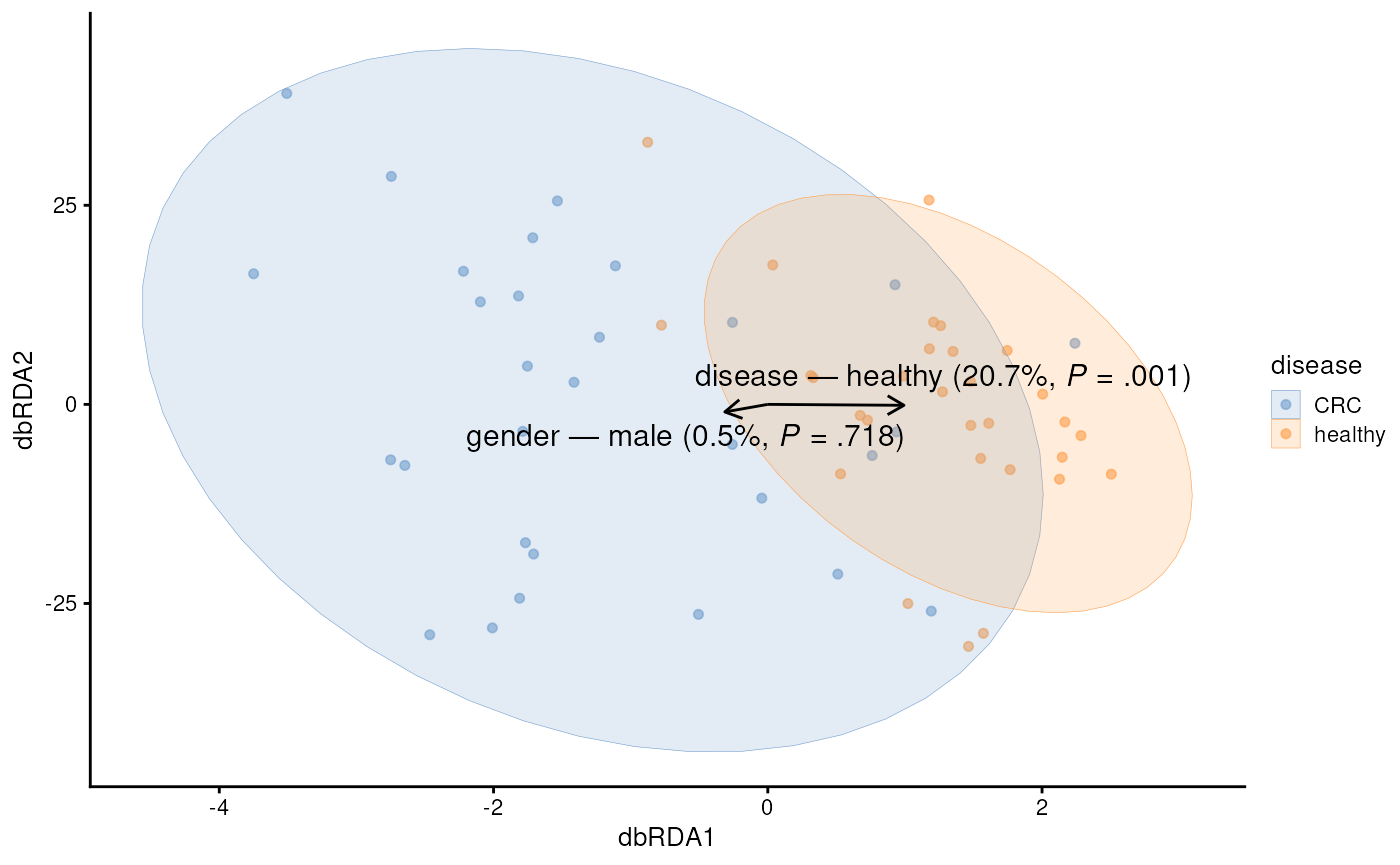
Feature loadings from the dbRDA analysis offer a first detailed look at the features that are associated with CRC.
plotLoadings(tse, dimred = "RDA", ncomponents = 2L, layout = "lollipop")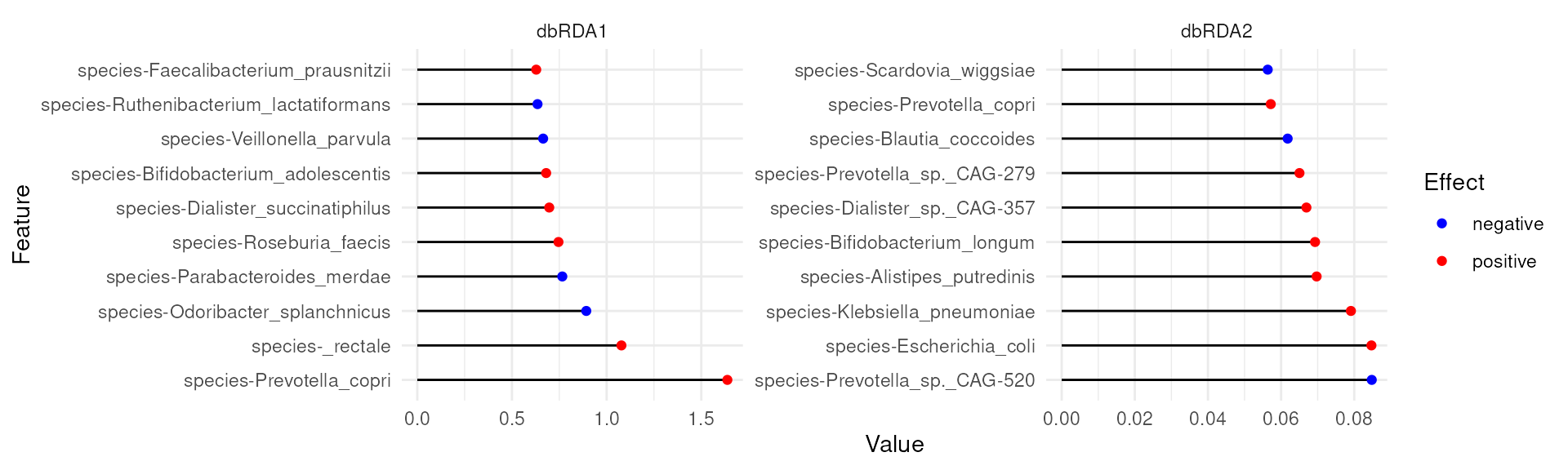
For instance, Prevotella copri is positively associated with the first coordinate (or x-axis in our biplot). Because, CRC was also positively associated with the first coordinate, this suggests association between higher abundance of Prevotella copri and CRC.
Questions, discussion and recap
- Microbiome data science in SummarizedExperiment ecosystem
- Scalable and computationally efficient
- Integration of multi-table and multi-omics datasets
Thank you for your time!
Join us!
- Online book: microbiome.github.io/OMA
- Discussion forums: github.com/microbiome/OMA/discussions and Bioconductor Zulip
![]()
Session information
sessionInfo()
#> R Under development (unstable) (2025-12-01 r89083)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.3 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Etc/UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] scater_1.39.0 scuttle_1.21.0
#> [3] miaViz_1.19.1 ggraph_2.2.2
#> [5] ggplot2_4.0.1 mia_1.17.11
#> [7] TreeSummarizedExperiment_2.19.0 Biostrings_2.79.2
#> [9] XVector_0.51.0 SingleCellExperiment_1.33.0
#> [11] MultiAssayExperiment_1.37.2 SummarizedExperiment_1.41.0
#> [13] Biobase_2.71.0 GenomicRanges_1.63.0
#> [15] Seqinfo_1.1.0 IRanges_2.45.0
#> [17] S4Vectors_0.49.0 BiocGenerics_0.57.0
#> [19] generics_0.1.4 MatrixGenerics_1.23.0
#> [21] matrixStats_1.5.0 ape_5.8-1
#>
#> loaded via a namespace (and not attached):
#> [1] RColorBrewer_1.1-3 jsonlite_2.0.0
#> [3] magrittr_2.0.4 TH.data_1.1-5
#> [5] estimability_1.5.1 ggbeeswarm_0.7.3
#> [7] farver_2.1.2 rmarkdown_2.30
#> [9] fs_1.6.6 ragg_1.5.0
#> [11] vctrs_0.6.5 memoise_2.0.1
#> [13] DelayedMatrixStats_1.33.0 ggtree_4.1.1
#> [15] htmltools_0.5.8.1 S4Arrays_1.11.1
#> [17] BiocNeighbors_2.5.0 janeaustenr_1.0.0
#> [19] cellranger_1.1.0 gridGraphics_0.5-1
#> [21] SparseArray_1.11.7 sass_0.4.10
#> [23] parallelly_1.45.1 bslib_0.9.0
#> [25] tokenizers_0.3.0 htmlwidgets_1.6.4
#> [27] desc_1.4.3 plyr_1.8.9
#> [29] DECIPHER_3.7.0 sandwich_3.1-1
#> [31] emmeans_2.0.0 zoo_1.8-14
#> [33] cachem_1.1.0 igraph_2.2.1
#> [35] lifecycle_1.0.4 pkgconfig_2.0.3
#> [37] rsvd_1.0.5 Matrix_1.7-4
#> [39] R6_2.6.1 fastmap_1.2.0
#> [41] tidytext_0.4.3 aplot_0.2.9
#> [43] digest_0.6.39 ggnewscale_0.5.2
#> [45] patchwork_1.3.2 irlba_2.3.5.1
#> [47] SnowballC_0.7.1 textshaping_1.0.4
#> [49] vegan_2.7-2 beachmat_2.27.0
#> [51] labeling_0.4.3 polyclip_1.10-7
#> [53] mgcv_1.9-4 abind_1.4-8
#> [55] compiler_4.6.0 fontquiver_0.2.1
#> [57] withr_3.0.2 S7_0.2.1
#> [59] BiocParallel_1.45.0 viridis_0.6.5
#> [61] DBI_1.2.3 ggforce_0.5.0
#> [63] MASS_7.3-65 rappdirs_0.3.3
#> [65] DelayedArray_0.37.0 bluster_1.21.0
#> [67] permute_0.9-8 tools_4.6.0
#> [69] vipor_0.4.7 beeswarm_0.4.0
#> [71] glue_1.8.0 nlme_3.1-168
#> [73] gridtext_0.1.5 grid_4.6.0
#> [75] cluster_2.1.8.1 reshape2_1.4.5
#> [77] gtable_0.3.6 fillpattern_1.0.2
#> [79] tzdb_0.5.0 tidyr_1.3.1
#> [81] hms_1.1.4 tidygraph_1.3.1
#> [83] BiocSingular_1.27.1 ScaledMatrix_1.19.0
#> [85] xml2_1.5.1 ggrepel_0.9.6
#> [87] pillar_1.11.1 stringr_1.6.0
#> [89] yulab.utils_0.2.2 splines_4.6.0
#> [91] tweenr_2.0.3 dplyr_1.1.4
#> [93] ggtext_0.1.2 treeio_1.35.0
#> [95] lattice_0.22-7 survival_3.8-3
#> [97] tidyselect_1.2.1 DirichletMultinomial_1.53.0
#> [99] fontLiberation_0.1.0 knitr_1.50
#> [101] fontBitstreamVera_0.1.1 gridExtra_2.3
#> [103] xfun_0.54 graphlayouts_1.2.2
#> [105] rbiom_2.2.1 stringi_1.8.7
#> [107] ggfun_0.2.0 lazyeval_0.2.2
#> [109] yaml_2.3.11 evaluate_1.0.5
#> [111] codetools_0.2-20 gdtools_0.4.4
#> [113] tibble_3.3.0 BiocManager_1.30.27
#> [115] ggplotify_0.1.3 cli_3.6.5
#> [117] xtable_1.8-4 systemfonts_1.3.1
#> [119] jquerylib_0.1.4 Rcpp_1.1.0
#> [121] readxl_1.4.5 coda_0.19-4.1
#> [123] parallel_4.6.0 pkgdown_2.2.0
#> [125] readr_2.1.6 sparseMatrixStats_1.23.0
#> [127] decontam_1.31.0 viridisLite_0.4.2
#> [129] mvtnorm_1.3-3 slam_0.1-55
#> [131] tidytree_0.4.6 ggiraph_0.9.2
#> [133] scales_1.4.0 purrr_1.2.0
#> [135] crayon_1.5.3 BiocStyle_2.39.0
#> [137] rlang_1.1.6 cowplot_1.2.0
#> [139] multcomp_1.4-29University of Turku, tvborm@utu.fi↩︎